

ElasticsearchとKibana Mapsを使い、東京都犯罪データの位置情報をローコードで可視化する方法を解説します。また、Logstashによる効率的なデータ取り込み手順も紹介します。
なぜ位置情報が重要なのか
位置情報は単なる点の座標データに留まりません。リアルタイム分析と組み合わせることで、以下のような価値あるインサイトが生まれます。
- 交通・MaaS: リアルタイムな混雑状況の把握や最適ルートの提案により、移動の効率化と利用者満足度の向上が可能。
- 物流: 配送ルートの最適化や燃料コスト削減など、輸送効率を最大化。トラックや荷物のリアルタイムトレーシングにより遅延やロスを迅速に検知できます。
- AIデバイス・セキュリティ: リアルタイムトレーシングによるデバイスや人の動態監視で異常検知や侵入警告を実現。設備の稼働状況を地図上で把握し、効率的な管理やメンテナンス計画に役立てられます。
このように、位置情報×リアルタイム分析は様々な業界で意思決定を支える重要な手法となっています。
Elastic Stackによる位置情報可視化の概要
Elastic Stackは、統合的なデータ収集・分析基盤です。本ブログで用いる主要コンポーネントは次のとおりです。
- Elasticsearch: スケーラブルで高速な検索・分析エンジン。位置情報を含む大規模データの格納と集計に適しています。
- Kibana: Elasticsearch上のデータを可視化・分析するためのダッシュボードツール。地理空間データ向けのMaps機能を備え、GUI操作で多彩なビジュアル化が可能です。
- Logstash: 多様なデータソースからのデータ収集・変換・送信を行うパイプラインツール。CSVなど構造化データの読み込みやリアルタイムデータ取り込みに適しており、シンプルな設定でElasticsearchへのデータ投入を自動化できます。
これらを組み合わせることで、大量の位置情報データをリアルタイムに取り込みつつ(Logstash)、それを高速検索エンジン(Elasticsearch)に蓄積し、最後にダッシュボード(Kibana)で地図可視化するという一連の流れが実現できます。
Elastic Mapsとは
Elastic MapsはKibanaに統合された地理空間データ可視化ツールです。Elasticsearchに格納された位置情報をインタラクティブな地図上にポイントやシェイプ、ヒートマップなどの形式で表示し、直感的な分析を可能にします。主な特徴をまとめると:
- 地理空間分析: IPアドレス由来の位置、GPS座標、行政区画ポリゴンなど、多様な地理情報を可視化できる。
- インタラクティブマップ: マップ上でのズーム・パン操作やフィルタリングにより、興味深いデータポイントを動的に探索可能。
- レイヤー機能: 複数のデータレイヤーを重ねて表示し、多角的な分析を実現(例: ポイントデータ+エリア境界+ヒートマップを同一マップ上に重ねる)。
- リアルタイム更新: データがElasticsearchに追加・更新されると、マップ表示にも即時反映されるリアルタイム連携。
- カスタマイズ性: ポイントの色やシンボル、サイズ、ラベル表示などを柔軟に設定可能。用途に応じてマップの見せ方を調整できます。
Elastic Mapsは、ネットワーク監視や物流管理、地理的なトレンド分析など幅広い用途で活用されています。利用するには、Elasticsearchのインデックスに地理情報フィールド(geo_point型またはgeo_shape型)が含まれていることと、Kibana上で当該インデックスにアクセスできることが必要です(※Elasticsearchの動的マッピングではgeo_pointを自動認識しないため、後述するように手動でマッピング定義を行います)。
データ準備
今回は、東京都のオープンデータである犯罪認知数のデータと、町丁目レベルの緯度・経度参照データを使用します。前者には東京都内の各区市町村・町丁目ごとの犯罪件数(罪種別・手口別)が含まれており、後者は各町丁目の代表地点の座標情報です。
データは以下のサイトから取得しました。
区市町村の町丁別、罪種別及び手口別認知件数:
https://www.keishicho.metro.tokyo.lg.jp/about_mpd/jokyo_tokei/jokyo/ninchikensu.html
国土数値情報ダウンロードサイト:
https://nlftp.mlit.go.jp/cgi-bin/isj/dls/_choose_method.cgi
取得した複数年分(2019年~2024年)のCSVを統合し、分析に適した形に前処理します。具体的には「区」「町丁目」を識別子とし、各罪種別・手口の件数をワイド形式(各カテゴリが列)からロング形式(各カテゴリが行レコード)へ変換しました。これにより、「区」「町丁」「緯度」「経度」「犯罪種別」「件数」「年」といった列を持つ一つの大きなデータセットを構築しています。件数0のレコードは分析上不要なため除去しました。最終的に約数万行規模のデータ(long_format_crime_data.csv)となりますが、目的はElasticsearchによる地図可視化機能の紹介であり、個々の犯罪傾向の考察は本稿の範囲外とします。
リアルタイムデータ取り込み: Python vs Logstashによるアプローチ
大量のCSVデータをElasticsearchに投入する方法として、まずはシンプルにPythonスクリプトを用いる方法と、Elastic Stack標準のLogstashを用いる方法の2つを試しました。それぞれのアプローチについて、実装手順と所感を比較します。
Pythonによるデータ投入
Pythonを使った方法では、pandasライブラリでCSVを読み込み前処理した後、ElasticsearchのPythonクライアント(またはREST API)でデータを登録するという手順を取りました。例えば、前述のワイド→ロング変換には以下のようなコードを使用しています。
import pandas as pd
# CSV複数ファイルを読み込み結合(2019-2023年分)
csv_files = ["crime_2019.csv", "crime_2020.csv", ...] # 各年のCSVファイル名
df_all = pd.concat([pd.read_csv(f) for f in csv_files], ignore_index=True)
# ワイド形式をロング形式に変換
df_long = df_all.melt(id_vars=["区", "町丁", "緯度", "経度", "Year"],
var_name="CrimeType", value_name="Count")
df_long = df_long[df_long["Count"].fillna(0).astype(int) > 0] # 件数0行を除去
変換後のdf_longデータフレームを1行ずつElasticsearchにインデックスしていきます。シンプルな実装としては以下のようになります。
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200") # Elasticsearchクライアント
for _, row in df_long.iterrows():
doc = {
"区": row["区"],
"町丁": row["町丁"],
"緯度": row["緯度"],
"経度": row["経度"],
"CrimeType": row["CrimeType"],
"Count": int(row["Count"]),
"Year": row["Year"],
"location": [float(row["経度"]), float(row["緯度"])] # 経度・緯度からgeo_point用配列生成
}
es.index(index="all_crimes", document=doc)
上記では各レコードを逐次投入していますが、データ件数が多い場合はかなり時間を要します(数万件規模で数分以上)。Pythonで細かな変換やロジックを実装できる柔軟性は魅力ですが、一件ずつの投入は非効率であり、リアルタイムデータ取り込みには適しません。大量データやストリーミングデータの取り込みには、次に述べるようにElastic Stackのツールを活用する方が効率的です。
Logstashによるデータ取り込み(ローコード実装)
Logstashを用いると、煩雑なコードを書くことなくローコードで大量データの取り込みパイプラインを構築できます。Logstashの設定ファイル(*.conf)にデータソースや処理内容を記述するだけで、CSV読み込みからElasticsearch送信までを自動化してくれます。Python実装と比較すると、大規模データでは圧倒的に高速であることが検証できました。
以下に、本稿で使用したLogstash設定ファイルの例を示します。(CSVファイルパスやフィールド名は環境に合わせて適宜読み替えてください。)

Logstashの実行方法
bin/logstash -f logstash_crime.conf※Elastic Stack を zip からインストールした場合、bin/logstash がコマンド。Homebrewなら logstash -f ...
上記のLogstash設定では、CSVフィルタで各列をパースし、日本語のフィールド名「緯度」「経度」をlocation_dataというオブジェクト配下に整理しています。続いてRubyフィルタでlocationというgeo_point形式の配列フィールドを生成し(経度・緯度の順に配置)、さらにYearからYearDateというdate型フィールドを作成しています。最後にElasticsearch出力では、作成済みのインデックスall_crimesにデータを書き込みつつ、pipelineオプションでIngest Pipeline(Elasticsearch側のデータ投入時処理)を指定しています。このremove_raw_fieldsパイプラインは、CSV読み込み時に付与される生のメッセージフィールド(messageや@version等)を削除するためのものです。
PUT _ingest/pipeline/remove_raw_fields
{
"processors": [
{ "remove": { "field": "message" }},
{ "remove": { "field": "event.original" }}
]
}
マッピングの設定: Logstashでデータ投入を行う前に、Elasticsearch側でインデックスのマッピングを用意しておくことが重要です。とくにlocationやYearDateのように、デフォルトの動的マッピングでは適切な型(geo_pointやdate)にならないフィールドは、あらかじめ明示的に型指定してインデックスを作成します。開発者ツール(Dev Tools)上で以下のようなコマンドを実行し、インデックスall_crimesを作成しました。
PUT all_crimes
{
"mappings": {
"properties": {
"location": { "type": "geo_point" },
"YearDate": { "type": "date", "format": "strict_year" },
"CrimeType": { "type": "keyword" },
"CrimeMethod": { "type": "keyword" },
"Count": { "type": "integer" }
}
}
}以上の設定により、Pythonスクリプトを用いた場合と比べて格段に高速に(体感で数十倍以上)データを投入できました。CSV数万件程度であれば数十秒~1分程度で完了し、Elasticsearchのインデックスにドキュメントが登録されます。Logstashは設定ファイルさえ用意すれば、リアルタイムにファイルを監視して継続的に取り込むことも可能であり、本番環境でも耐えうる柔軟かつ強力なデータ取り込み基盤となります。
Kibana Mapsでの可視化
データの準備と投入が完了したら、いよいよKibanaのMaps機能を使って位置情報データを可視化してみましょう。ここでは、Elasticsearchにロードしたall_crimesインデックス上の地理データを地図にプロットし、さらに集計表示や時系列による変化も確認できるダッシュボードを作成します。
※注意:Kibana上での可視化には、対応するData Viewの作成が必要です。
Kibanaは「どのインデックスに、どんな構造のデータがあるか」を認識するために、このData Viewを参照します。忘れずにインデックスに対応するData View を作成しておきましょう。
ベースマップの追加
最初に地図の土台となるベースマップを追加します。Kibanaのナビゲーションメニューから「Maps」を開き、「Create map」ボタンをクリックしてください。その後、以下の手順でベースマップレイヤーを設定します。
- 「Add layer」→「EMS Basemaps」
- お好みのスタイルを選択しましょう(例えば視認性の高い”Light”スタイルなど)→「Add and continue」
- 必要に応じてベースマップの表示設定を調整します。今回は地図をはっきり表示するため「Opacity(不透明度)」を100%に設定し、「Label language」を日本語に変更しました。
- 「Keep changes」をクリックします。
以上で背景地図となるベースマップが追加されます。選択したスタイルによる白地図が表示され、これからプロットするデータの土台として機能します。
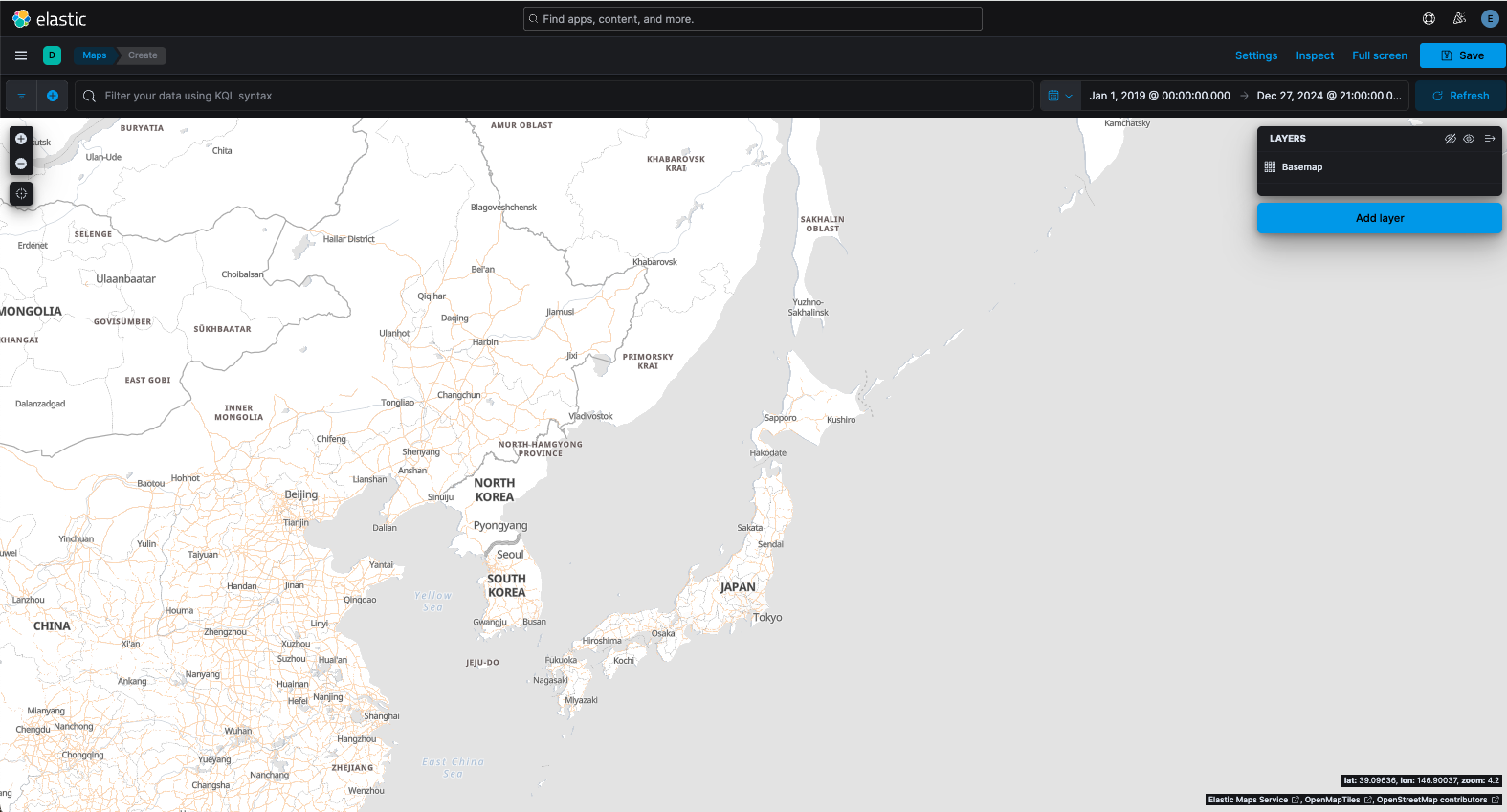
データレイヤー(ドキュメント)の追加
続いて、Elasticsearchに投入した位置情報データ(犯罪データ)のレイヤーを地図に重ねます。ベースマップと同様に「Add layer」から操作します。手順は次のとおりです。
- 「Add layer」→「Documents」(Elasticsearchに保存されたドキュメントを直接プロットするレイヤーです)
- 「Data view」→ 可視化したいものを選択
- 「Geospatial field」→ 自動的に
locationが選択されている - 「Add and continue」→ 地図上にデータポイントがプロットされ始めます
- 必要に応じて表示範囲(ズームレベル)を制限できます。例えば本ケースでは東京都付近を詳細表示したいため、「Visibility」を
[9, 24]に設定しました。 - ポイントを選択した際に表示される詳細情報「Tooltip fields」を設定します。表示したいフィールド(例:
CrimeType、Year、区など)を追加します。これにより各ポイントにマウスオーバーすると、選択した項目の値が吹き出しで表示されます。 - 「Layer style」の項目ではデータポイントの見た目をカスタマイズできます。「Fill color」を適当なカラーグラデーションに設定し(件数に応じて色が変わるよう設定も可能)、「Symbol size」を「By value」に変更して
Count(件数)フィールドを指定します。これで犯罪件数が多い地点ほどシンボルが大きく描画されるようになります。必要であれば「Label」欄にCountを指定し、各ポイント上に件数ラベルを直接表示させることもできます。 - 「Keep changes」をクリックします。
以上の設定により、地図上に東京都内の各地点がプロットされ、それぞれの点について件数や犯罪種別などの情報を確認できるようになります。ポイントの大小や色で事件数の多寡がひと目で分かり、マウスオーバーで詳細な内訳も把握できます。
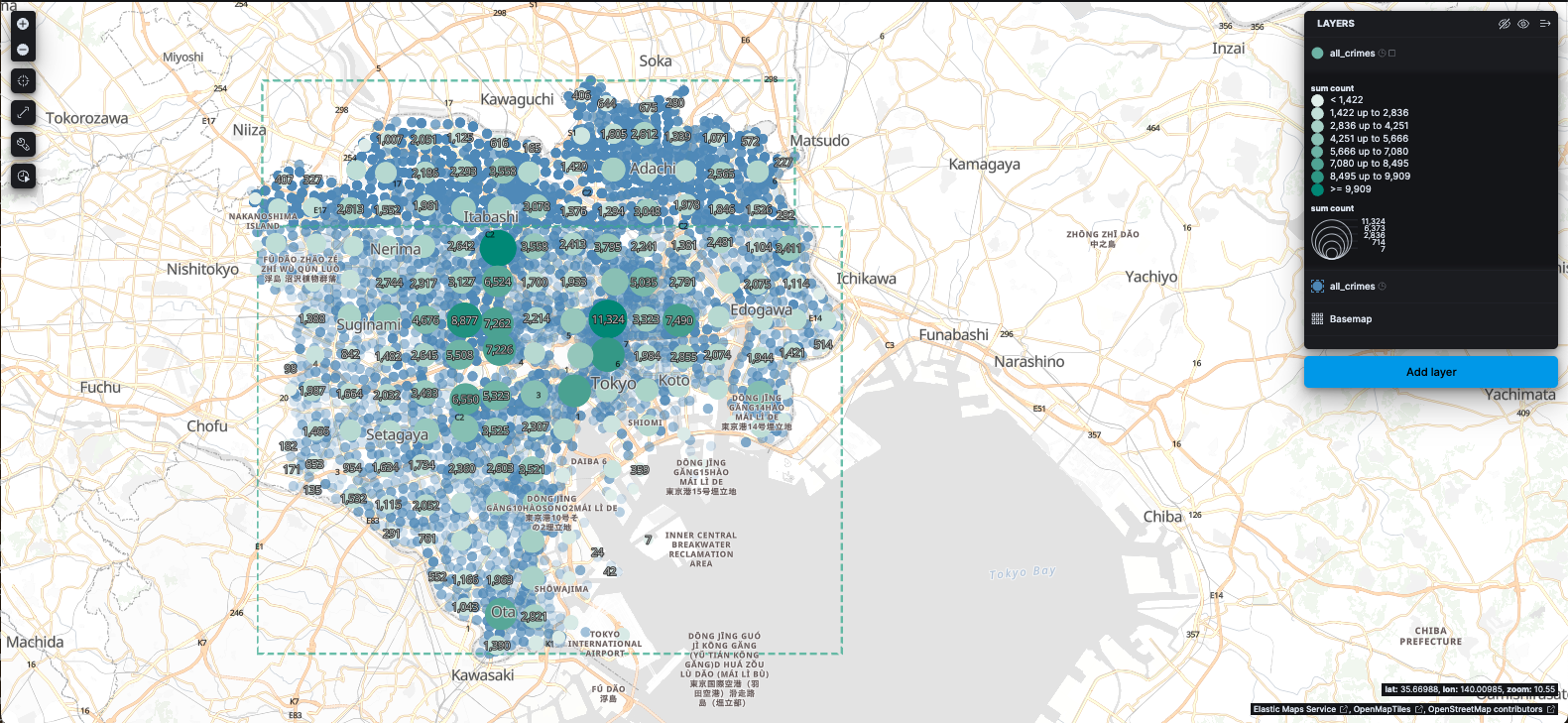
all_crimesインデックスのドキュメントをポイントレイヤーとして地図にプロットした結果です。町丁目単位の地点ごとに犯罪件数(Count)に応じた大小の青い円で表示しています。また各円内に件数ラベルを表示しているため、密集地帯でもおおよその数値を読み取ることができます(このラベル表示は任意設定です)。地図を拡大縮小したりドラッグしたりすることで、関心エリアを詳細に調べられます。クラスタレイヤーの追加とタイムスライダーの活用
個々のポイントが多くプロットされる場合、クラスタリング機能を使うと可視化が見やすくなります。Kibana Mapsではドキュメントレイヤーとは別にクラスタレイヤーを追加することで、ポイントの密集地を自動的にグルーピングして表示可能です。また時系列データであればタイムスライダーを使って時間変化をアニメーション再生することもできます。ここでは、件数データの集約表示とタイムスライダーについて説明します。
クラスタレイヤーの追加手順:
- 「Add layer」→ 「Clusters」
- 対象Data viewを指定→ 「Add and continue」
- 「Show as」で集計の形式を選択します。「Clusters」(円形のクラスター表示)か「Grids」(格子状のグリッド集計)または「Hexagons」(六角形グリッド)から選べます。今回はClustersを選択しました。
- 「Metrics」→ Aggregation →
sum→ FieldにCount(「Add metrics」で複数集計も可能) - 「Cluster size」(Resolution)でクラスタリングの細かさを調整できます。値を高くすると細かいグリッドでクラスタリングされ、値を低くすると大まかな範囲でまとめられます。デフォルト設定で問題なければそのままで構いません。
- 「Keep changes」をクリックします。
クラスタレイヤーを適用すると、ポイントが密集しているエリアでは一つの大きな円でまとめて表示されるようになります。円の中の数字はそのクラスタ内の件数合計(今回設定ではCrime件数の総和)を表します。これにより、例えば23区内のどの地域に犯罪が多発しているかを一望でき、分布の傾向を把握しやすくなります。また、ズームインすれば自動的にクラスターが細分化され、ズームアウトすれば再度まとまるといった具合に、可視化の粒度が動的に変化します。


さらに、タイムスライダー機能を使うと時間経過に沿ったデータの変化をアニメーション表示できます。今回のデータは年単位の集計値ですが、タイムスライダーを有効にすると地図下部に再生バーが表示され、時系列でデータの増減を確認できます。画面左の時計アイコン(緑の矢印で示したボタン)をクリックするとスライダーが表示され、再生ボタンでアニメーション開始です。

ダッシュボードでの活用とフィルタリング
作成した地図はKibanaのダッシュボードに組み込んで活用できます。Maps画面右上の「Save」ボタンから地図を保存し、適宜タイトルを付けて保存します。保存時に既存のダッシュボードに追加するか、新規ダッシュボードを作成するオプションがありますので、「Save and add to dashboard」を選択するとよいでしょう。別の場所でこの図を使用する場合は、「Add to library」にチェックを入れましょう。(ライブラリに追加された要素は「Visualize Library」で確認できます。)

ダッシュボードでは複数の可視化(グラフや地図)を一画面に配置して総合的に分析できます。Kibanaダッシュボードの強力な点は、フィルタリングが連動することです。あるパネルで範囲を絞り込むと、同じダッシュボード上の他の全パネルに一括でそのフィルターが適用されます。これにより、例えば地図上で特定の地域を選択すると、他のグラフやテーブルもその地域のデータにリアルタイムに絞り込まれるため、関連性のある指標を横断的に分析することが可能です。

もう一つの便利な機能がシェイプでの領域フィルターです。地図パネル上で任意の図形を描画し、その範囲内のデータだけにダッシュボード全体をフィルタリングできます。使い方は以下のとおりです。
- 「Tools」→ 「Draw shape to filter data」
- 任意の図形を描画。
すると、その描画した図形(ポリゴン)に該当するエリア内のデータだけがフィルターされます。他のグラフパネルも同時にそのフィルター条件が適用された状態に更新されます。
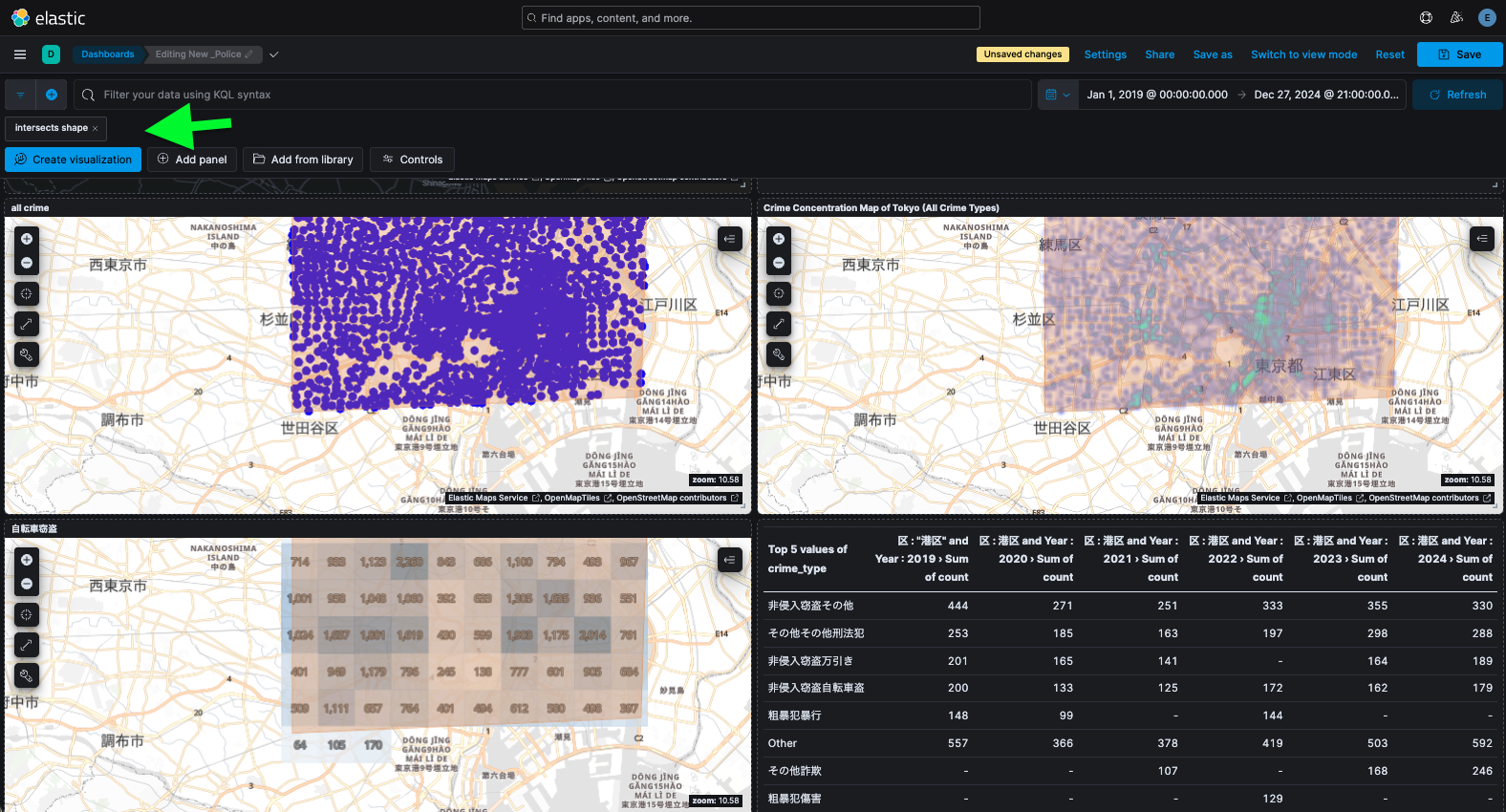
たとえば東京23区西部を囲む長方形を描けば、その範囲に含まれる町丁の犯罪件数データのみが地図および関連グラフに反映されます。フィルター適用中は画面上部に「intersects shape」というフィルターラベルが表示されます。解除したい場合はそのラベルの✖ボタンをクリックすれば元の全データ表示に戻ります。
さらに、ダッシュボードでは地図パネル以外にも通常のフィルターバーやクエリバーが使用可能です。右側のフィルタリングメニューや上部の検索バーにKQL(Kibana Query Language)を書いてフィルターを適用することもできます。(例えば、区 :"世田谷区" and CrimeType : "侵入窃盗(空き巣)" and YearDate >= "2020" といったクエリを投入すれば、「世田谷区で発生した侵入窃盗(空き巣)が2020年以降に限定」した条件で全パネルを絞り込めます。)
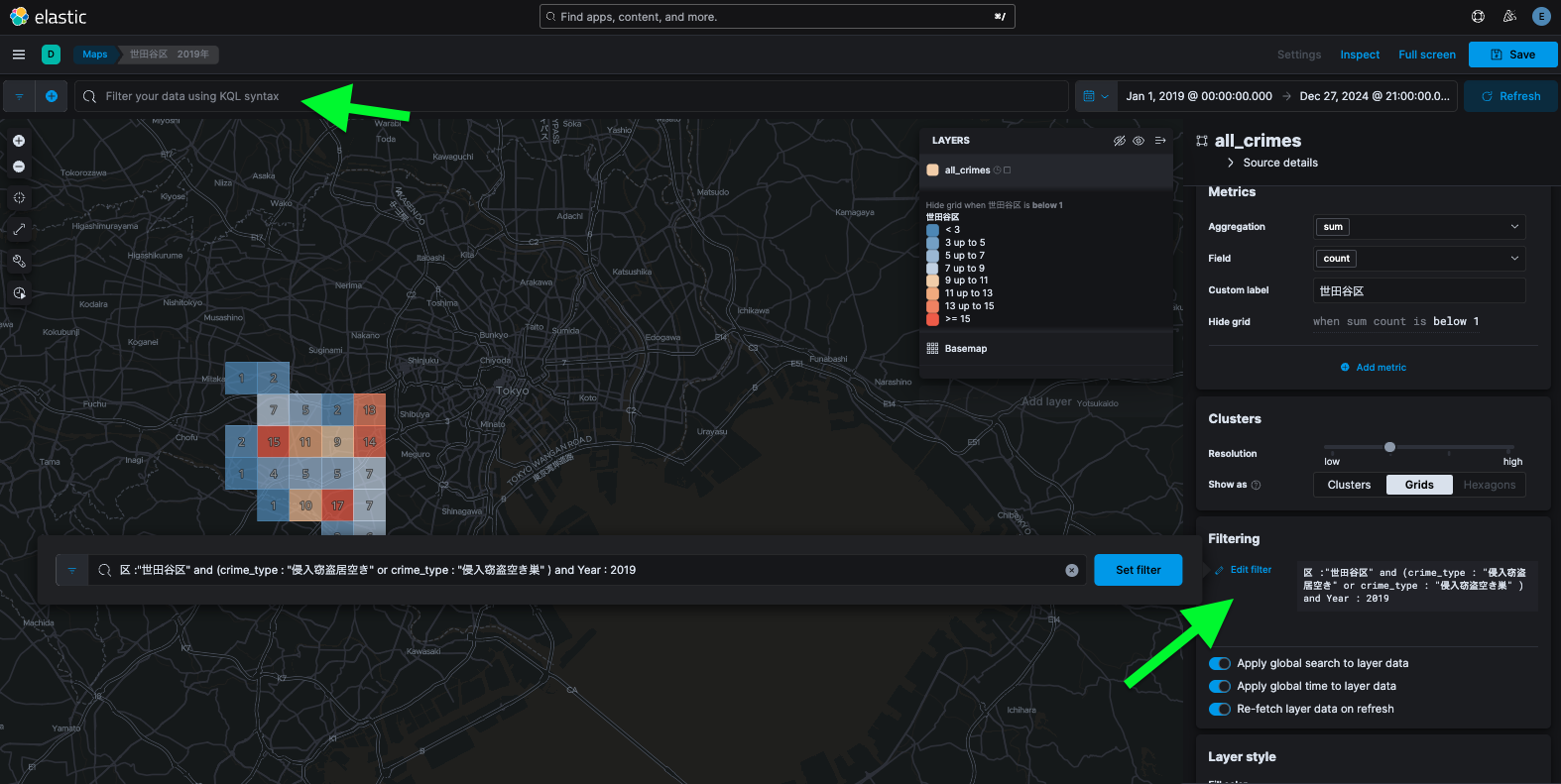
最後に、Kibana Mapsの高度な機能としてES|QLを使用したレイヤー追加も挙げられます。今回の例では使用しませんでしたが、Add layer時に「Documents」ではなく「ES|QL」を選ぶことで、Elasticsearchに対してSQLライクなクエリを発行し、その結果を地図レイヤーとして可視化することも可能です。
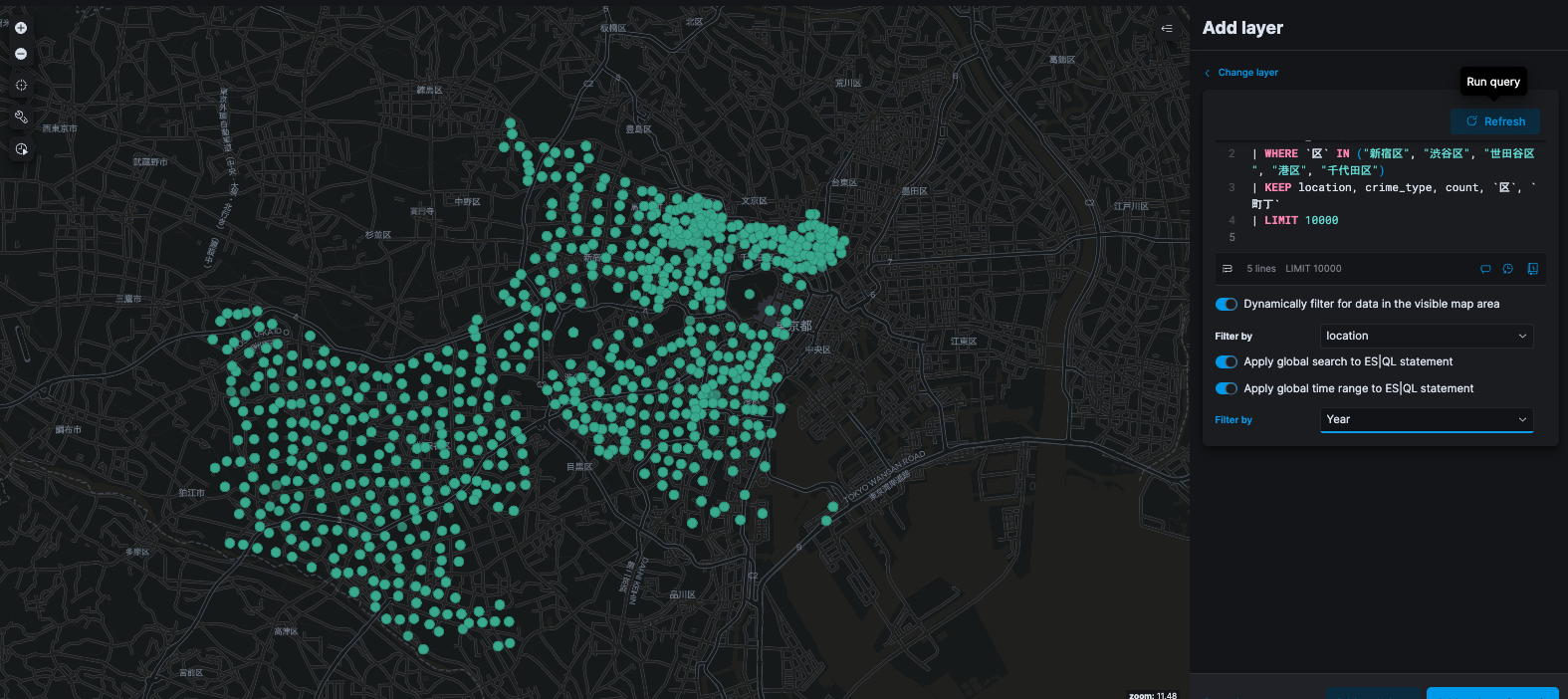
FROM all_crimes
| WHERE 区 IN (“新宿区”, “渋谷区”, “世田谷区”, “港区”, “千代田区”)
| KEEP location, crime_type, count, 区, 町丁
| LIMIT 10000
大量データの集約結果やサブクエリを用いた特殊な可視化を行いたい上級者向けの機能ですが、状況に応じて活用すると分析の幅がさらに広がるでしょう。
スケーラビリティのポイント
位置情報データを継続的に扱うシステムを設計する際には、スケーラビリティ(可搬性・拡張性)の確保が重要です。以下に、本記事の内容を実運用に展開する際に考慮すべきポイントをまとめます。
- データ投入パフォーマンス: 今回Logstash経由で高速化を図ったように、より大規模なデータではElasticsearchのBulk APIを活用して一括投入することで効率を上げられます。
- インデックス設計: データ量が膨大になる場合、一つのインデックスに集約しすぎると検索・集計性能が低下します。適切に時間単位でインデックスを分割したり(例えば年ごと・月ごとの名前で分割)、Elasticsearchのロールオーバー機能やILM(Index Lifecycle Management)ポリシーを導入して古いデータをアーカイブするといった戦略が有効です。
- クラスタリング表示の活用: Kibana Mapsで非常に多数のポイントを表示するとブラウザ描画が重くなる可能性があります。今回使用したクラスタレイヤーやグリッド表示を活用し、高ズームアウト時には集約表示、ズームイン時に詳細表示とすることでパフォーマンスと可読性を両立できます。
セキュリティの考慮事項
位置情報データはその性質上、個人や組織の行動範囲を含むセンシティブな情報を含む場合があります。Elastic Stackを用いてこれらを可視化・分析する際には、以下のセキュリティ面での対策・配慮が重要です。
- アクセス制御: KibanaダッシュボードやMapsアプリへのアクセスは、Elastic認証機能を利用して適切な権限設定を行いましょう。例えば社内向けポータルとして運用する場合、閲覧できるインデックスやダッシュボードをユーザロールごとに制限し、不要なデータ露出を防ぎます。
– Kibana → 管理 → 「Roles」機能で権限設定
– Userごとに「read」「write」「view_index_metadata」などを設定 - プライバシー保護: 個人を特定できる粒度の位置情報(GPS座標や詳細住所など)を扱う際は、必要に応じて匿名化(ジオフェンスで丸める、IDをハッシュ化する等)することを検討してください。
まとめ
ElasticsearchとKibana Mapsを活用することで、リアルタイムかつ直感的に位置情報データを可視化・分析できることを見てきました。リアルタイムデータ取り込みにおいてはLogstashが大規模データにおいて優れたパフォーマンスを示し、コードを書く手間を少なくしてスピーディーにデータ基盤を構築できる点が確認できました。Kibana Maps上ではポイント表示からクラスタリング、時系列アニメーション、ダッシュボード統合まで豊富な機能をローコードで実現でき、ビジネス課題に応じた柔軟な地理空間分析が可能です。
本ブログでは機能紹介に留まりましたが、実際のユースケースに合わせて応用すれば可能性は非常に広がります。例えば、機械学習を組み合わせて異常な移動パターンを検知したり、ベクター検索技術と統合して位置情報と他の高次元データを関連付けることも考えられます。
位置情報の高速可視化は、今後ますます重要になるリアルタイムデータ活用の一領域です。ぜひ皆さんのプロジェクトでもElasticsearchとKibana Mapsを活用し、地理空間データから新たな価値を引き出してみてください。
使用環境・ツールバージョン
本記事の検証・実装に使用した主なツールのバージョンは以下のとおりです:
| ツール | バージョン |
|---|---|
| Elasticsearch | 8.17.3 |
| Kibana | 8.17.3 |
| Logstash | 8.17.3 |
| Python | 3.9.18 |
※バージョンによってUIや挙動に差異がある場合があります。あらかじめご了承ください。

