

「社内のドキュメントを、ChatGPTのように対話形式で検索できたら…」 「ノーコードツールでプロトタイプを作りたいけど、検索精度が物足りない…」
そんな悩みを抱える業務改善担当者の方へ。本記事では、オープンソースのワークフロー自動化ツール n8n と、強力な検索エンジン Elasticsearch を組み合わせ、実用的な RAGシステムを構築する方法を説明します。
完成後のAIチャットボットが、以下のようなものになります。
- データ検索: 映画のタイトル、監督、ジャンル、あらすじなど、複数の要素を横断して検索します。
- 自然言語での対話: 「アクション映画でおすすめは?」といった曖昧な質問にも的確に応答します。
- 会話記憶: 文脈を理解した、人間らしいスムーズな対話を実現します。
なぜこの技術スタックなのか?n8n, Elasticsearch, LLMの強力なシナジー
このシステムの中核をなすのが「RAG」という考え方です。これは、外部の知識データベースから関連情報を「検索(Retrieve)」し、その情報を基に大規模言語モデル(LLM)が回答を「生成(Generate)」する技術です。これにより、LLMが元々知らない情報(例:自社データ)についても、正確な回答が可能になります。
今回の構成では、各ツールがRAGにおいて完璧な役割分担を果たします。
- Retriever (検索役): Elasticsearch
- Generator (生成役): OpenAI (GPT-3.5/4)
- Orchestrator (指揮者): n8n
これら3つを繋ぎ合わせ、データの前処理からユーザーとの対話まで、一連の流れを自動化するのがn8nの役割です。ノーコード/ローコードの直感的なUIで複雑なロジックを組める柔軟性が、今回のシステム構築を可能にします。
その前に:n8nとは?
ここまでn8nという名前が当たり前のように出てきましたが、ここで改めてその正体と、なぜ今多くの技術者から注目されているのか、その魅力について説明します。
n8n(エヌ・エイト・エヌ「nodemation」の略)は、2019年に誕生したオープンソースのワークフロー自動化ツールです。
一言でいえば、様々なデジタルサービスやツールを、まるでパズルのピースをはめ込むように自由に組み合わせて、定型業務を自動化できるプラットフォームです。
n8nが他のツールと一線を画し、技術者・非技術者にとって強力な武器となる理由は、主に以下の3点に集約されます。
- オープンソースによる柔軟性とコントロール:n8nは、クラウド版とセルフホスト版から選択可能です。
- ノーコードとプロコードの融合:ドラッグ&ドロップで簡単に自動化でき、JavaScriptやPythonでの拡張も可能です。
- 豊富な接続性:数百種類のサービス(Gmail、Slack、Notionといった日常的なツールから、AWS、Google Cloud、MCPまで)に対応し、インテリジェントなシステム構築を可能にする「司令塔」として機能します。
単純作業の自動化で時間を生み出すだけでなく、今回のように複数の高度な技術を連携させ、新たな価値を創造する。n8nは、そんな「攻めの自動化」を実現するためのプラットフォームなのです。
この強力な自動化ツールを指揮者として、いよいよ具体的なシステム構築に入っていきましょう。
必要な準備
- n8n(今回のバージョン;セルフホストv.1.97.1)
- Elasticsearch(今回のバージョン;9.0.3)
- OpenAI API(GPT-3.5/4)
- CSVファイル(映画データ:LLMを使用して、架空の映画のcsvのデータセットを作成した。カラムはタイトル、ジャンル、監督、作成年、映画紹介となります。90編の映画の情報が入っています。)
n8nの使い方: 最初のステップ
n8nを始めるための具体的な手順を、クラウド版とセルフホスト版それぞれについて説明します。
クラウド版
一番手軽に始める方法です。公式サイトからサインアップすれば、すぐに利用を開始できます。
- 14日間の無料トライアルが提供されています。まずは公式サイトにアクセスし登録してみましょう。
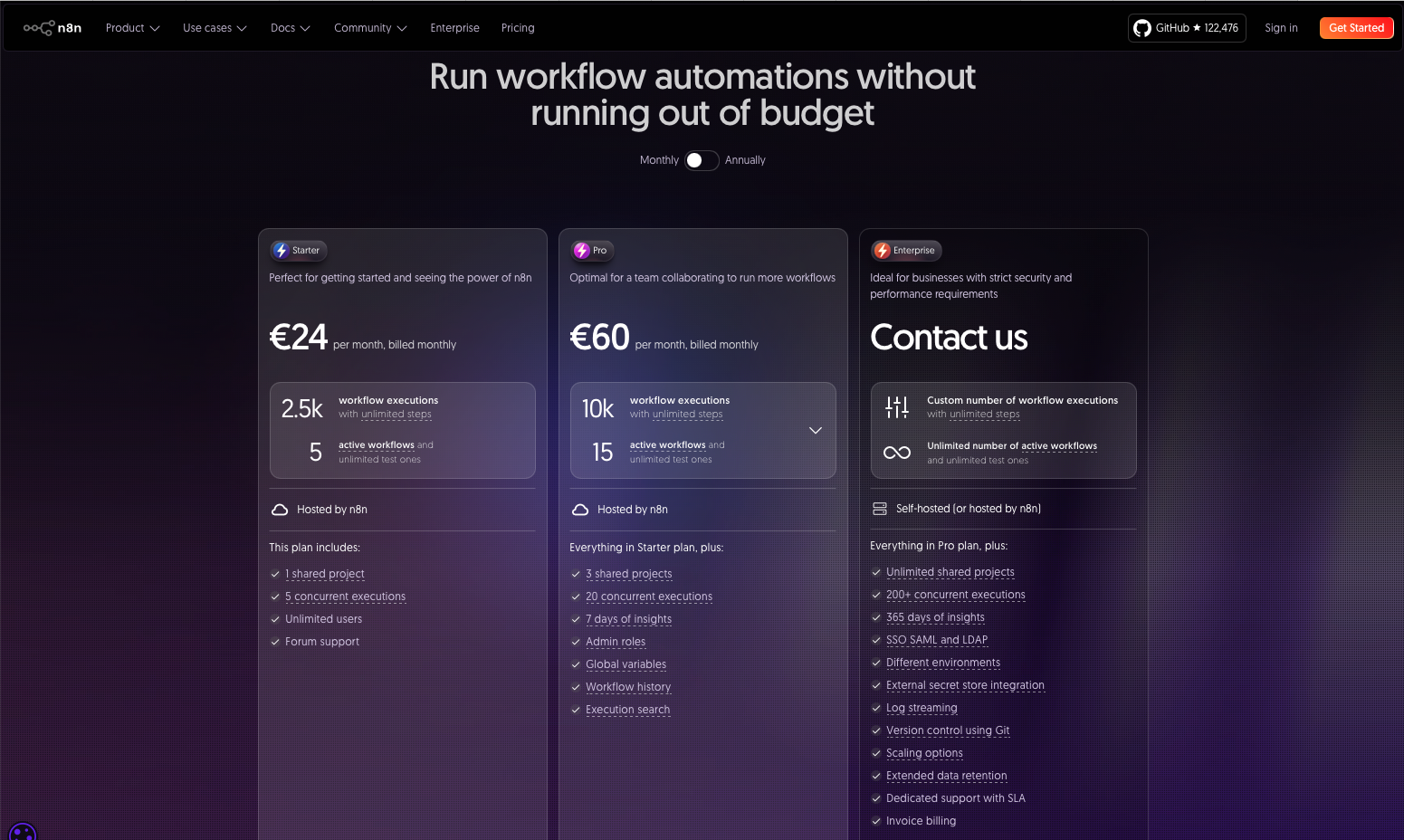
- トライアル期間終了後の料金プランは公式サイトでご確認ください。2025年7月23日現在の料金プランは以下の通りです。
セルフホスト版
ご自身のPCやサーバーでn8nを動かす方法です。
- 前提条件: PCにNode.jsがインストールされている必要があります。
- インストール: ターミナル(コマンドプロンプト)を開き、以下のコマンドを実行するだけでn8nがダウンロードされます。
npx n8n- 起動: ダウンロード後、同じくターミナルで以下のコマンドを実行します。
n8n - 起動が完了すると、ブラウザで
http://localhost:5678/にアクセスすることでn8nの画面を開くことができます。
この記事ではn8nの詳細な使用方法については触れませんが、後の手順でスムーズに進められるよう、主要な画面について簡単に説明します。
起動後、何もないキャンバスが表示されます。画面中央または右上のプラスアイコンをクリックしてノードを選択します。
右側からノードリストが表示されます。
検索欄から目標のものを検索できます。

ターゲットのノードをキャンバスにドラッグ&ドロップします。
プラスのマークをクリックして次のノードに繋げます。まだ設定が完了していないので赤いマークが表示されている。
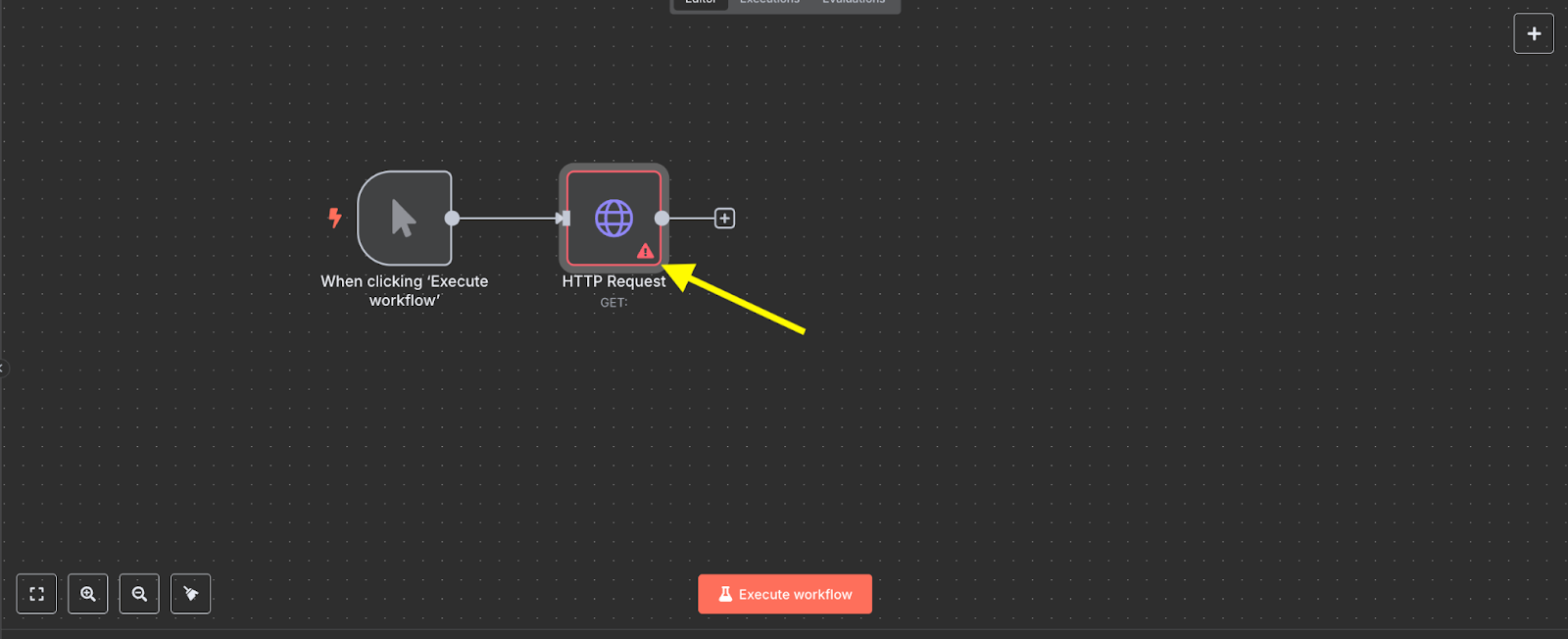
ノードをダブルクリックすると設定画面が開きます。後ほど説明します。
今回構築したワークフロー
このワークフローは、CSVファイルから映画データを読み込み、Elasticsearchに保存し、OpenAI GPTを活用した自然言語での映画検索を可能にします。
大きく分けて2つの部分で構成されています:
パート1:セットアップフロー(データベース構築)
まず、AIの知識源となる映画データをElasticsearchに投入(インデックス)します。
こちらのワークフローの目的は、CSVデータを読み込み、いつでも検索できる形でElasticsearchに保存することです。主に「①CSV読み込みと整形」「②Elasticsearchへの登録」というステップで構成されます。
1. Setup Trigger(セットアップトリガー)
- 役割:ワークフローを手動で開始するトリガー
- ノード:Manual Triggerを使用
2. Check Index Exists(インデックス存在確認)
- 役割:Elasticsearchに「movies3」という名前のインデックスが既に存在するかチェック
- ノード:HTTP Request
- 設定詳細:
- メソッド:HEAD
- URL:https://localhost:9200/movies3
- 認証:Basic認証(Elasticsearchの認証情報)
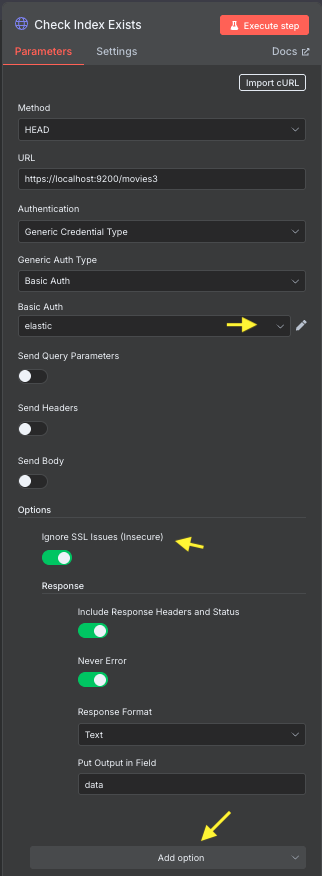
Basic AuthのプールダウンからCreate new credentialを選びます。
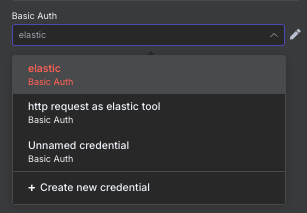
elasticのIDとパスワードを入力します。画面の左上をダブルクリックするとノード名が変えられます。
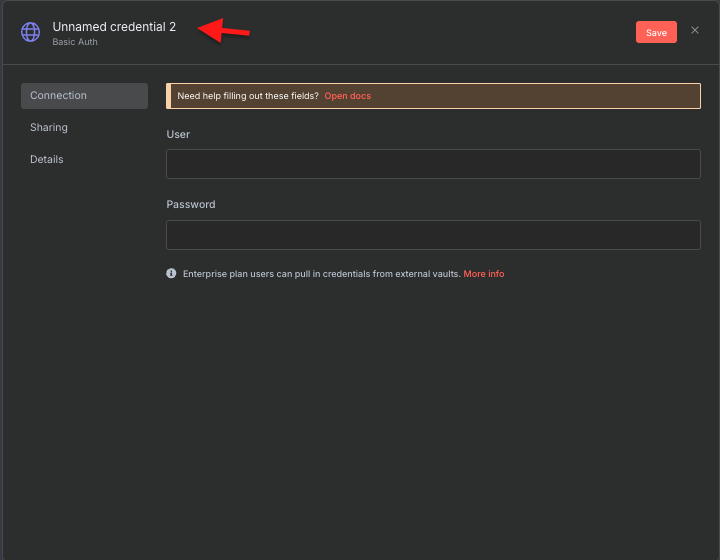
今回、設定を簡単にするためにIgnore SSLを使いました。画面下のAdd optionをクリックすると選択できます。
Parametersタブ以外にSettingsタブもありますが今回は使用しません。
3. Index Exists?(条件分岐)
- 役割:インデックスの存在状況に基づいて処理を分岐
- ノード:IF
- 設定:条件判定
- 条件:$response.statusCode == 404(存在しない場合)
- 分岐:
- True(存在しない)→ 新規作成へ
- False(存在する)→ 削除してから新規作成へ
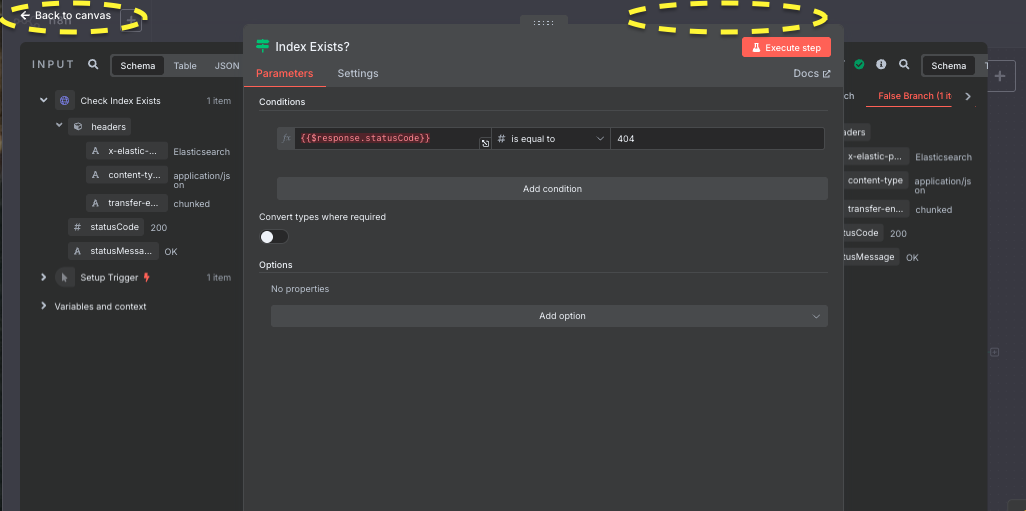
※設定画面を閉じたい場合、黄色のエリアをクリックします。
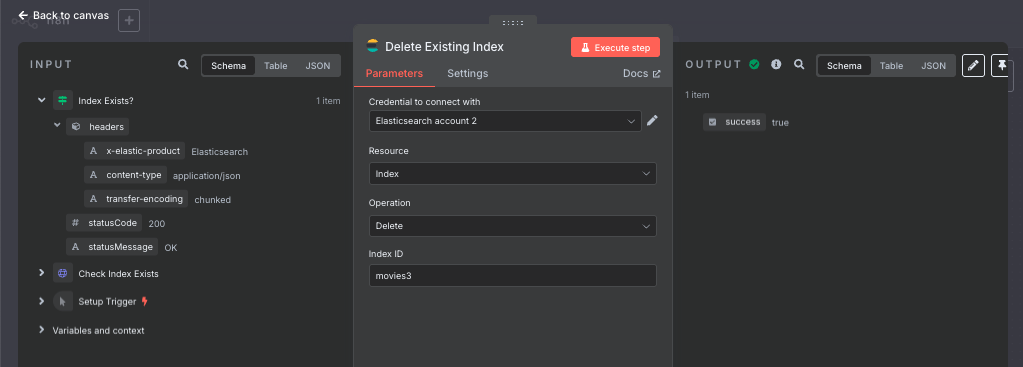
4. Delete Existing Index(既存インデックス削除)
- 役割:既存のインデックスを削除
- ノード:Elasticsearch
- 設定:
- リソース:Index
- オペレーション:Delete
- インデックスID:movies3
5. Create Index(インデックス作成)
- 役割:新しいElasticsearchインデックスを作成
- ノード:Elasticsearch
- 設定:
- リソース:Index
- オペレーション:Create
- インデックスID:movies3

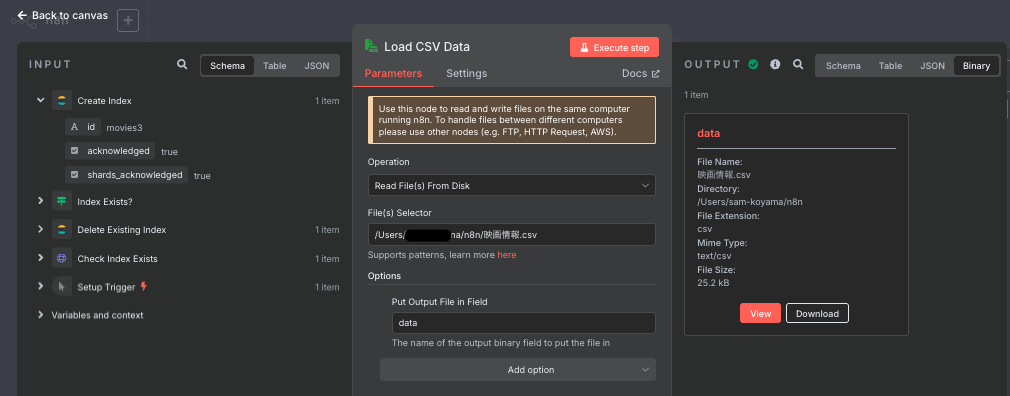
6. Load CSV Data(CSVデータ読み込み)
- 役割:ローカルファイルからCSVデータを読み込み
- ノード:Read/Write File
- 設定:
- ファイルパス:/Users/※※※/n8n/映画情報.csv (ファイルパスは自分の環境に合わせて変更が必要です)
- データプロパティ名:data
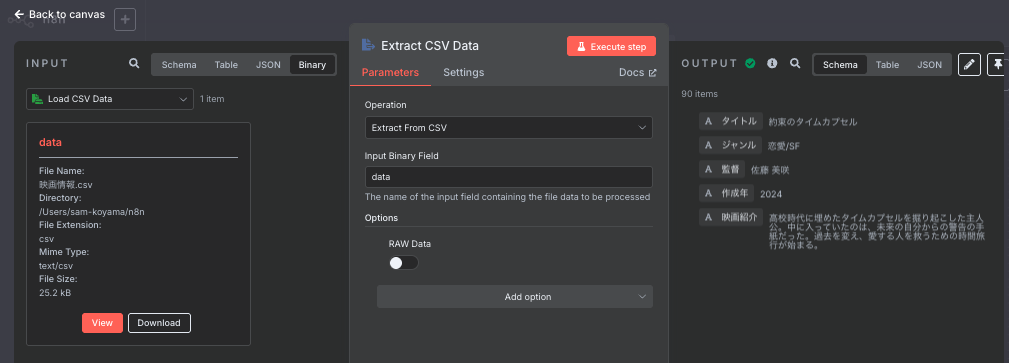
7. Extract CSV Data(CSV解析)
- 役割:読み込んだCSVファイルを構造化データに変換
- ノード:Extract from File
設定:Raw Dataを無効化してJSONとして解析
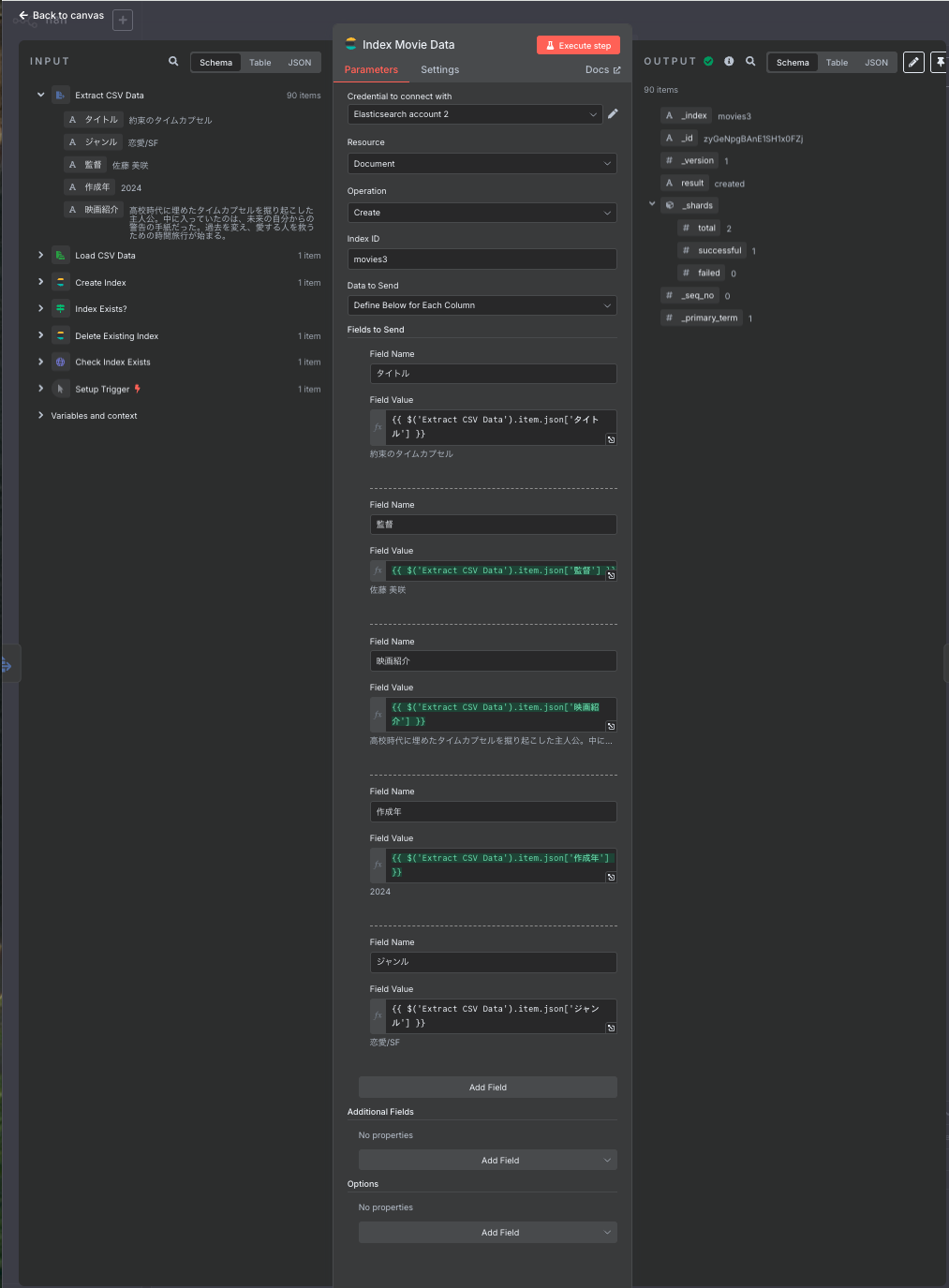
8. Index Movie Data(映画データインデックス化)
- 役割:解析したCSVデータをElasticsearchに保存
- ノード:Elasticsearch
- 設定詳細:
- オペレーション:Create
- インデックスID:movies3
- フィールドマッピング:
- タイトル ← CSVのタイトル列
- 監督 ← CSVの監督列
- 映画紹介 ← CSVの映画紹介列
- 作成年 ← CSVの作成年列
- ジャンル ← CSVのジャンル列
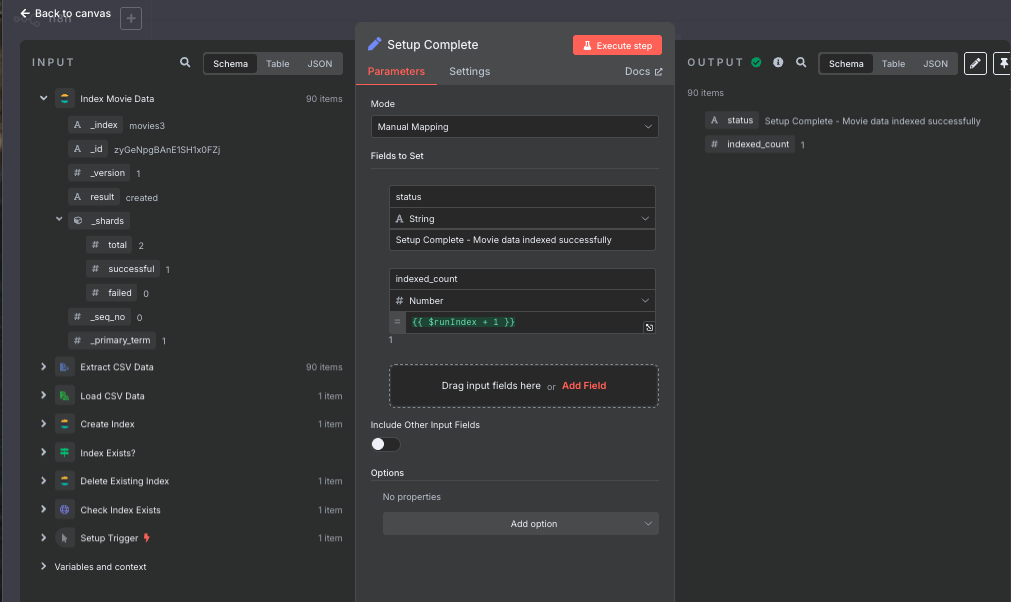
9. Setup Complete(セットアップ完了)
- 役割:セットアップの完了状況を記録
- ノード:Set
- 出力:完了メッセージとインデックス化されたレコード数
これで最初のフローが完成しました。
右下にある緑の✅がうまく動いていたとの意味になります。

パート2:チャットボットフロー(実際の検索・応答)
次に、ユーザーからの質問にAIが答えるためのフローを構築します。
このワークフローの目的は、ユーザーの質問をトリガーに、LangChainのAIエージェントが自律的に思考・行動し、最適な回答を返すことです。AIエージェントは、必要に応じて専用検索ツール、Elasticsearch を呼び出し、関連情報を取得します。
10. When chat message received(チャットメッセージ受信)
- 役割:ユーザーからのチャットメッセージを受信するトリガー
- ノード:Chat Trigger
- 設定:メッセージを受信
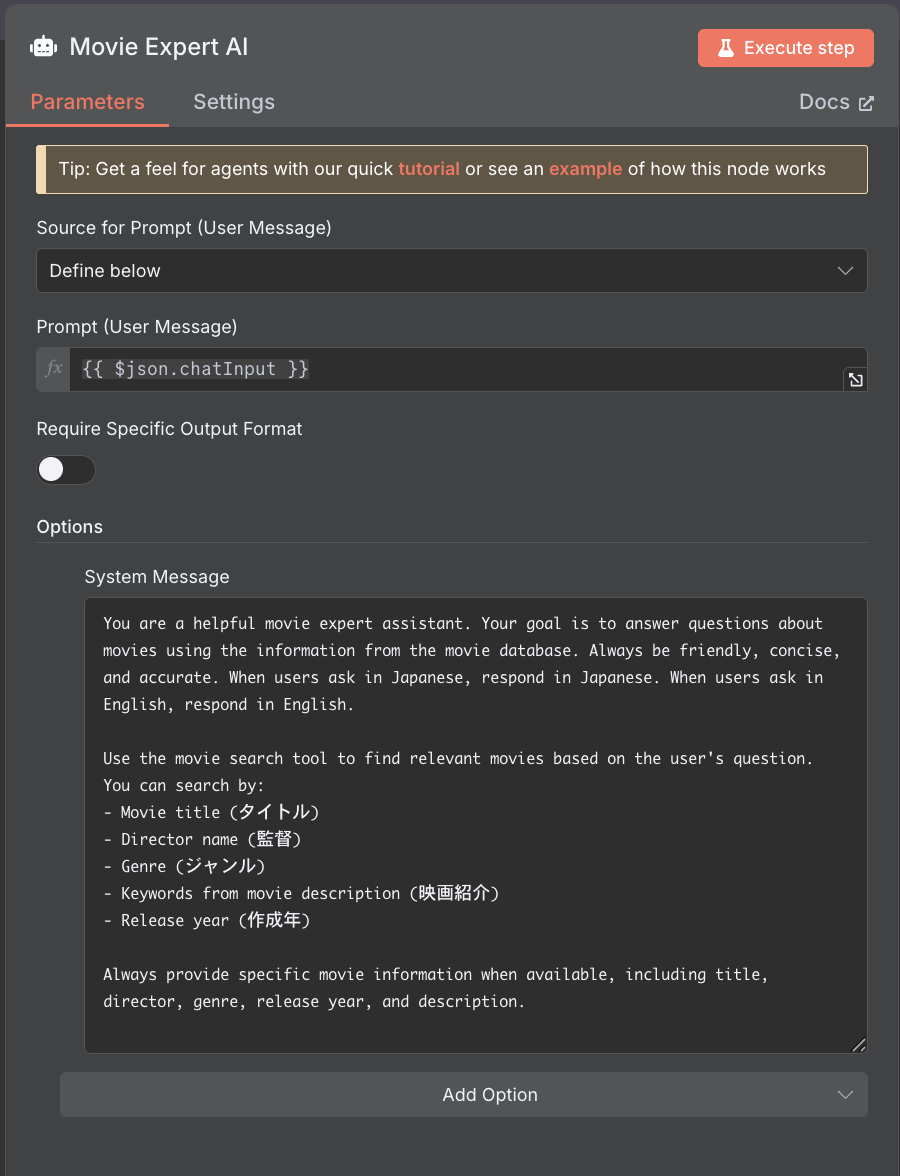
11. Movie Expert AI(AI エージェント)
- 役割:チャットボットの中核となるAIエージェント
- ノード:AI Agent
- システムメッセージ
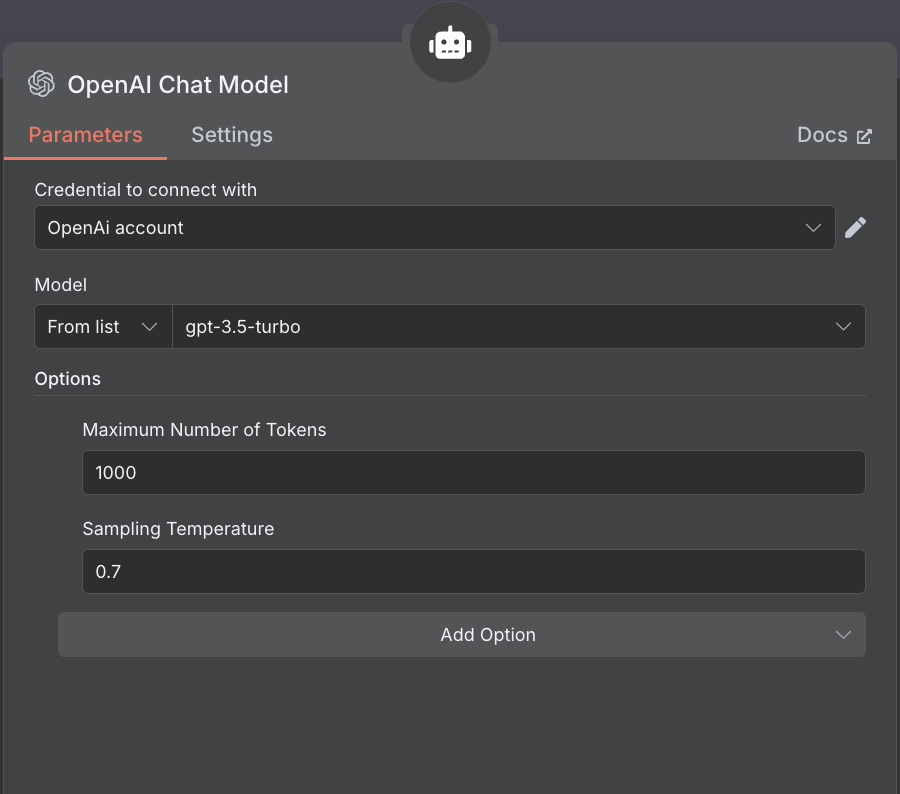
12. OpenAI Chat Model(言語モデル)
- 役割:自然言語理解と生成を担当
- ノード:OpenAI Chat Model
- 設定:
- モデル:gpt-3.5-turbo
- 最大トークン:1000
- 温度:0.7(創造性のバランス)
Credential to connect withからCreate new credentialを選んでOpenAIのAPIを入力する必要があります。
13. Movie Search Tool(映画検索ツール)
- 役割:Elasticsearchでの映画検索を実行
- ノード:HTTP Request Tool

検索クエリの詳細:
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "{{ $parameter.searchText }}",
"fields": [
"タイトル^3",
"監督^2",
"ジャンル^2",
"映画紹介^1"
],
"type": "best_fields",
"fuzziness": "AUTO",
"operator": "or"
}
},
{
"wildcard": {
"タイトル.keyword": "*{{ $parameter.searchText }}*"
}
}
]
}
}
}検索の特徴:
- bool / should: ここに含まれる条件のいずれかに一致すれば結果として返されます。「OR検索」のような振る舞いをし、検索の網羅性を高めます 。
- multi_match: ユーザーからの検索語 {{ $parameter.searchText }} を、複数のフィールド (タイトル, 監督など) に対して同時に検索します 。
- fields とブースト (^3): ここがチューニングの要です。「タイトル」フィールドの重要度を3倍、「監督」「ジャンル」を2倍にしています 。これにより、検索語が紹介文に含まれるだけの映画よりも、タイトルそのものに含まれる映画が、より関連度が高いと判断され、検索結果の上位に表示されます。
- fuzziness: “AUTO”: ユーザーが多少タイポしても(例:「インターステラ」を「インタステラー」と入力)、Elasticsearchが賢く解釈して正しい映画を見つけてくれます 。
- wildcard: multi_matchが単語単位での検索なのに対し、こちらは部分一致を可能にします 。例えば「スター」と検索すれば「スター・ウォーズ」がヒットするようになります。このように性質の異なる検索方法を
- shouldで組み合わせることで、検索の精度と網羅性を両立させています。
- size: 5: 検索結果を最大5件に絞り込み、LLMに渡す情報量を適切にコントロールします 。
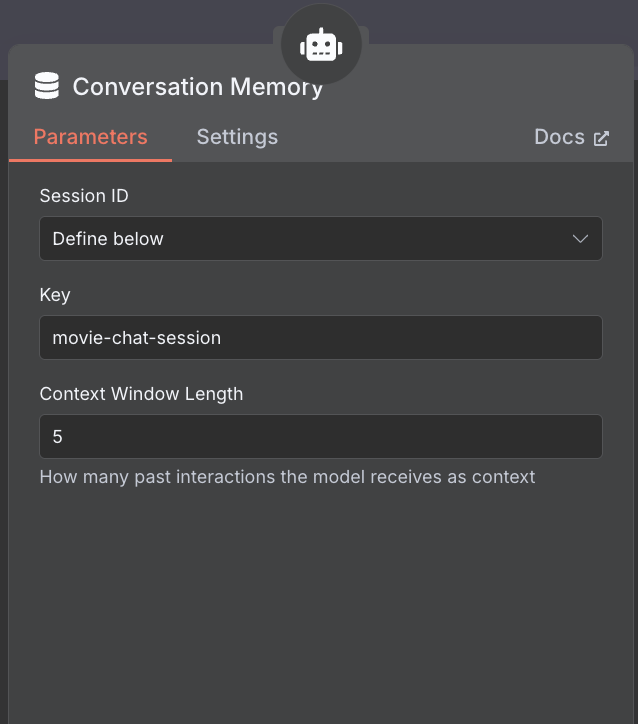
14. Conversation Memory(会話記憶)
- 役割:対話の文脈を記憶・維持
- ノード:Memory Buffer Window
- 設定:セッションキー「movie-chat-session」で会話を識別
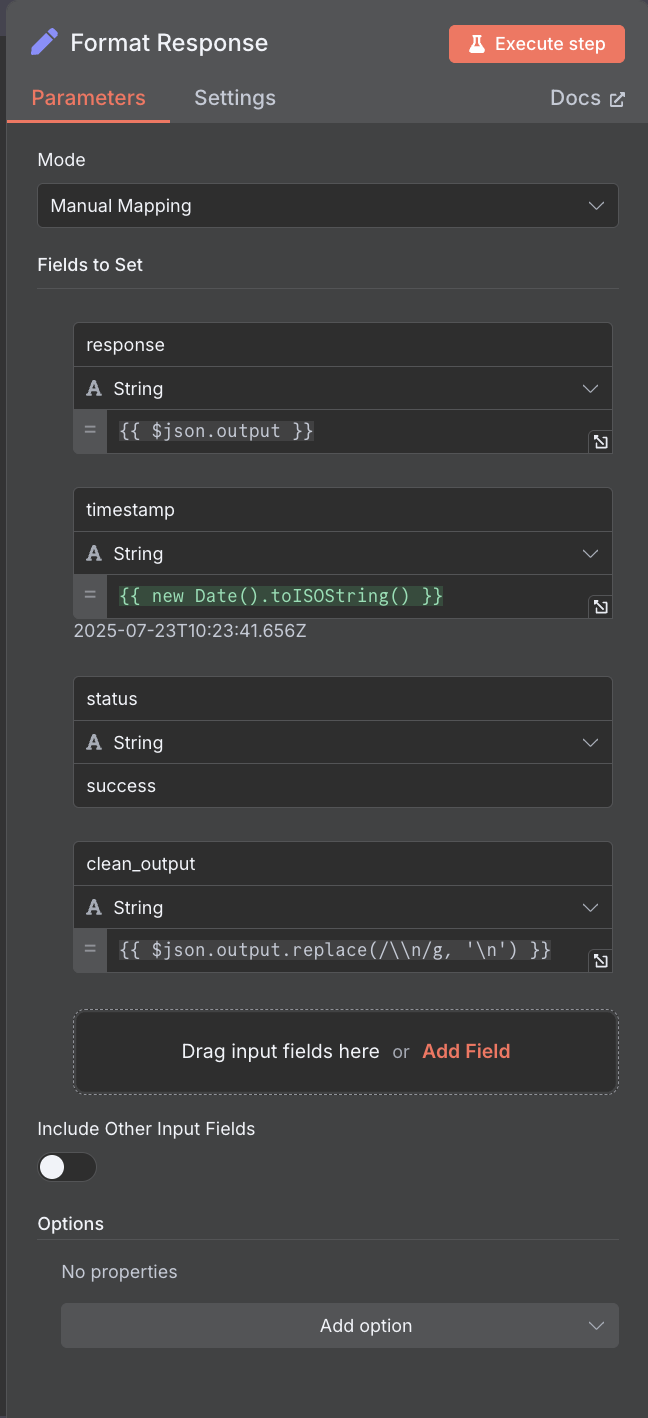
15. Format Response(レスポンス整形)
- 役割:AIの回答を整形して返す
- ノード:Set
- 出力項目:
- response:AIの回答
- timestamp:回答時刻
- status:処理状況
- clean_output:整形済み回答
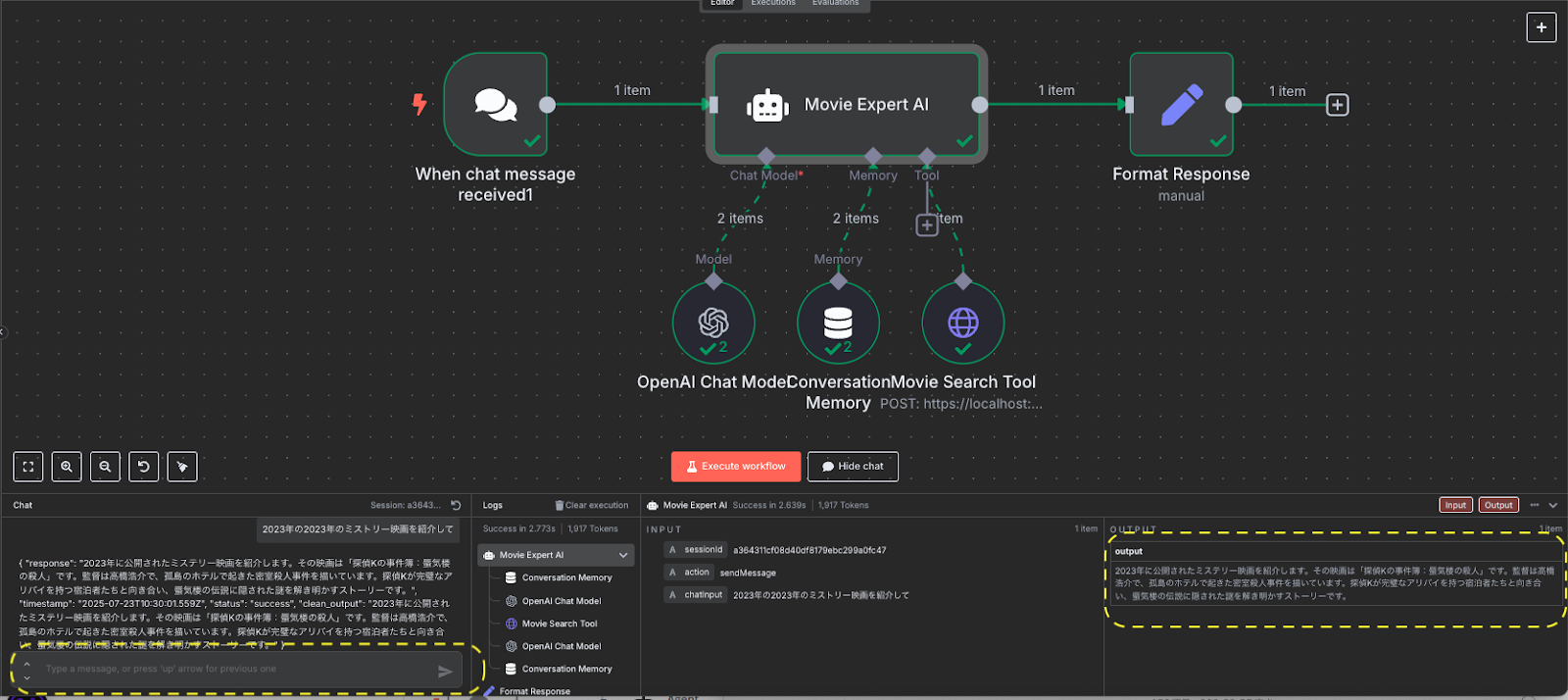
これで最後のフローが完成しました。
右下にある緑の✅がうまく動いていたとの意味になります。
左下の黄色の点線が質問を書くとこになります。
作成手順のまとめ
ステップ1:環境準備
- n8nをインストール・起動
- Elasticsearchをインストール・起動
- OpenAI APIキーを取得
- 映画データCSVファイルを準備
ステップ2:認証情報の設定
- n8nの「Credentials」でElasticsearch認証情報を作成
- OpenAI API認証情報を作成
- HTTP Basic認証情報を作成
ステップ3:セットアップフローの構築
- Manual Triggerノードを配置
- HTTP Requestノードで存在確認を設定
- IFノードで条件分岐を作成
- Elasticsearchノードでインデックス操作を設定
- ファイル読み込み・解析ノードを配置
- データインデックス化ノードを設定
ステップ4:チャットボットフローの構築
- Chat Triggerノードを配置
- LangChain AgentノードでAIエージェントを設定
- OpenAI Chat Modelノードを接続
- HTTP Request Toolで検索機能を実装
- Memory Buffer Windowで記憶機能を追加
- Setノードで回答整形を設定
ステップ5:接続とテスト
- 全ノードを適切に接続
- セットアップフローを実行してデータを投入
- チャットボットをテストして動作確認
トラブルシューティング
よくある問題と解決策
1. Elasticsearch接続エラー
- 症状:「Connection refused」エラー
- 解決策:Elasticsearchが起動しているか確認、URLとポート番号を確認
2. CSVファイル読み込みエラー
- 症状:「File not found」エラー
- 解決策:ファイルパスを正しく設定、ファイルの存在を確認
3. OpenAI API呼び出しエラー
- 症状:「Unauthorized」エラー
- 解決策:APIキーが正しく設定されているか確認
4. 日本語文字化け
- 症状:日本語が正しく表示されない
解決策:CSVファイルの文字エンコードをUTF-8に設定
機能拡張のアイデア
- このシステムは出発点ですが、さらに進化させることも可能です。
- ベクトル検索への移行: 今回はキーワードベースの検索が中心でしたが、Elasticsearchのベクトル検索機能を活用すれば、「宇宙がテーマの壮大な映画」のような、より抽象的な意味での類似映画検索が可能になります。
- Kibanaでの可視化連携: Elasticsearchとセットで使われる可視化ツールKibanaを連携させれば、「年代別の映画ジャンル構成」などをダッシュボードで分析できます 。
- 音声入力対応: n8nのWhisperノードなどを組み合わせれば、音声で質問できるチャットボットへの拡張も夢ではありません 。
- MCP(Model Context Protocol)の導入
n8n は MCP クライアント/サーバー機能をベータ公開しており、AI エージェントが外部ツールや n8n の別ワークフローを連携しやすくなっています。
たとえば、Elasticsearch 検索後に別のデータベースをGPTに問い合わせたり、Slack通知やファイル出力ワークフローを「AI による判断で自動実行」するといった高度な連携がノーコードで可能です。
私もこのプロジェクトは初めてのトライでしたが、まず基本的な構成で動作させてから、段階的に機能を追加していくことをお勧めします。このチャットボットをベースに、様々な分野のデータベース検索システムに応用することが可能です。
参考リンク
- n8n公式ドキュメント
- https://github.com/n8n-io/n8n
- Elasticsearch公式ガイド Elasticの14日間無料期間もあります。
- OpenAI API ドキュメント
- LangChain ドキュメント

